Basic
tb1.map (item => ({ aliasName: item.col1 }))
SELECT fieldName AS aliasName FROM tb1 AS t1SELECT fieldName aliasName FROM tb1 t1SELECT fieldName AS aliasName FROM tb1 AS t1SELECT fieldName aliasName FROM tb1 t1SELECT fieldName AS aliasName FROM tb1 AS t1SELECT fieldName aliasName FROM tb1 t1SELECT fieldName AS aliasName FROM tb1 AS t1SELECT fieldName aliasName FROM tb1 t1SELECT fieldName AS aliasName FROM tb1 AS t1SELECT fieldName aliasName FROM tb1 t1SELECT fieldName AS aliasName FROM tb1 AS t1SELECT fieldName aliasName FROM tb1 t1SELECT fieldName AS aliasName FROM tb1 AS t1SELECT fieldName aliasName FROM tb1 t1
db.getCollection ("tb1").find ()findOne ()find ({}, {// 默认会显示 _id 字段 不显示其他字段; 0 显示该字段 1 显示该字段
A1:C5选中单元格列A行1到列C行5)
tb1.reduce (res, item) => { if (!res.includes (item.col1)) { res.push (item.col1) } return res }, [])new Set(tb1.map (item => item.col1))]
SELECT DISTINCT * FROM SELECT DISTINCT * FROM SELECT DISTINCT * FROM SELECT DISTINCT * FROM SELECT DISTINCT * FROM SELECT DISTINCT * FROM SELECT DISTINCT * FROM db.tb1.distinct ("personName")
-
tb1.map (item => ({find (item2 => item.col0 === item2.col0)
LEFT JOIN LEFT JOIN LEFT JOIN LEFT JOIN LEFT JOIN LEFT JOIN LEFT JOIN
db.tb1.aggregate ([$lookup : {from : 'tb2',localField : "_id", // tb1的字段 foreignField : "_id", // tb2的字段 as : "joinedData"$unwind : {path : "$joinedData",preserveNullAndEmptyArrays : true // 保留左边集合没有匹配的记录
RIGHT JOIN RIGHT JOIN RIGHT JOIN RIGHT JOIN RIGHT JOIN RIGHT JOIN RIGHT JOIN -
INNER JOIN INNER JOIN INNER JOIN INNER JOIN INNER JOIN INNER JOIN INNER JOIN
db.tb1.aggregate ([$lookup : {from : 'tb2',localField : "_id", // tb1的字段 foreignField : "_id", // tb2的字段 as : "joinedData"$match : {$joinedData : { $ne: [] }, // 只保留匹配的记录
-
FULL JOIN FULL JOIN FULL JOIN FULL JOIN FULL JOIN FULL JOIN -
tb1.filter (item => item.col1.match (/^regExp$/) && item.col2 === target)
WHERE conditionWHERE conditionWHERE conditionWHERE conditionWHERE conditionWHERE conditionWHERE condition
.find ()find ({"_id": ObjectEd("5ebc5eb5ebc5ebc5ebc5ebcc5ebc")})aggregate ({$match : {"field1": "someValue" } // 单个条件 aggregate ([{$match : {"field1": "someValue" } // 多个条件
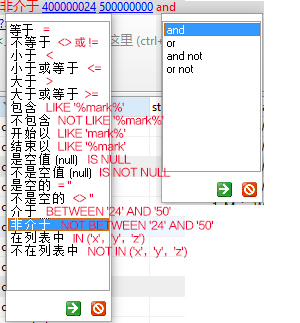
选择1个或多个column设置过滤条件
AND/OR
AND/OR
AND/OR
AND/OR
AND/OR
AND/OR
AND/OR
AND/OR
.find ({$and : [$gte : 10 }},$lt : 20 }},find ({$or : [$and : [$gte : 10 }},$lt : 20 }},$eq : "someValue" }},
=AND (condition1, [conditiona2], ...)AND (condition1, [conditiona2], ...)NOT (condition)结果为TRUE或FALSE
=
col = 'abc'
col = 'abc'
col = 'abc'equals (col, 'abc')
col = 'abc'
col = 'abc'
col = 'abc'
col = 'abc'
.find ({ "field1": "someValue" })
=H24=3
!=
col != 'abc'
col != 'abc'
col != 'abc'notEquals (col, 'abc')
col != 'abc'
col != 'abc'
col != 'abc'
col != 'abc'
.find ({ "field1": { $ne : "someValue" } })
=H24<>3
<
col < 100
col < 100
col < 100less (col, 100)
col < 100
col < 100
col < 100
col < 100
.find ({ "field1": { $lt : "someValue" } })
=H24<3
>
col > 100
col > 100
col > 100greater (col, 100)
col > 100
col > 100
col > 100
col > 100
.find ({ "field1": { $gt : "someValue" } })
=H24>3
<=
col <= 100
col <= 100
col <= 100lessOrEquals (col, 100)
col <= 100
col <= 100
col <= 100
col <= 100
.find ({ "field1": { $lte : "someValue" } })
=H24<=3
>=
col >= 100
col >= 100
col >= 100greaterOrEquals (col, 100)
col >= 100
col >= 100
col >= 100
col >= 100
.find ({ "field1": { $gte : "someValue" } })
=H24>=3
Contains
col LIKE '%abc%'like 可适用于数值日期, like 后可用单/双引号
col LIKE '%abc%'LIKE '_abc_' 中间为abc的长度为5的字符串 like 不适用于数值日期, like后只能用单引号
col LIKE '%abc%'like (col, '%abc%')like 不适用于数值日期, like后只能用单引号, 函数区分大小写
col LIKE '%abc%'like 不适用于数值日期, like后可用单/双引号
col LIKE '%abc%'LIKE '_abc_' 中间为abc的长度为5的字符串 like 可适用于数值日期, like后只能用单引号
col LIKE '%abc%'LIKE '_abc_' 中间为abc的长度为5的字符串 like 可适用于数值日期, like后只能用单引号
col LIKE '%abc%'LIKE '_abc_' 中间为abc的长度为5的字符串 like 可用于数值日期, like后只能用单引号
.find ({ "field1": /.*someValue.*/i })
=COUNTIF (B10,"*abc*")>0
Does not contain
col NOT LIKE '%abc%'
col NOT LIKE '%abc%'
col NOT LIKE '%abc%'notLike (col, '%abc%')
col NOT LIKE '%abc%'
col NOT LIKE '%abc%'
col NOT LIKE '%abc%'
col NOT LIKE '%abc%'
.find ({ "field1": { $not : /.*someValue.*/i } })
=COUNTIF (B10,"*abc*")=0
Begin with
col LIKE 'abc%'
col LIKE 'abc%'
col LIKE 'abc%'like (col, 'abc%')
col LIKE 'abc%'
col LIKE 'abc%'
col LIKE 'abc%'
col LIKE 'abc%'
.find ({ "field1": /^someValue.*/i })
=COUNTIF (B10,"abc*")>0
Does not begin with
col NOT LIKE 'abc%'
col NOT LIKE 'abc%'
col NOT LIKE 'abc%'notLike (col, 'abc%')
col NOT LIKE 'abc%'
col NOT LIKE 'abc%'
col NOT LIKE 'abc%'
col NOT LIKE 'abc%'
.find ({ "field1": { $not : /^someValue.*/i } })
=COUNTIF (B10,"abc*")=0
End with
col LIKE '%abc'
col LIKE '%abc'
col LIKE '%abc'like (col, '%abc')
col LIKE '%abc'
col LIKE '%abc'
col LIKE '%abc'
col LIKE '%abc'
.find ({ "field1": /.*someValue$/i })
=COUNTIF (B10,"*abc")>0
Does not end with
col NOT LIKE '%abc'
col NOT LIKE '%abc'
col NOT LIKE '%abc'notLike (col, '%abc')
col NOT LIKE '%abc'
col NOT LIKE '%abc'
col NOT LIKE '%abc'
col NOT LIKE '%abc'
.find ({ "field1": { $not : /.*someValue$/i } })
=COUNTIF (B10,"*abc")=0
is null
col IS NULL
col IS NULL
col IS NULL isNull (col)
col IS NULL
col IS NULL
col IS NULL
col IS NULL
.find ({ "field1": null })
-
is not null
col IS NOT NULL
col IS NOT NULL
col IS NOT NULL isNotNull (col)
col IS NOT NULL
col IS NOT NULL
col IS NOT NULL
col IS NOT NULL
.find ({ "field1": { $ne : null } })
Is empty
col = ''
col = ''
col = ''
col = ''
col = ''
col = ''
col = ''
.find ({ "field1": "" })
=ISBLANK (B8)
Is not empty
col != ''
col != ''
col != ''
col != ''
col != ''
col != ''
col != ''
.find ({ "field1": { $ne : "" } })
=NOT (ISBLANK (B8))
Is between
col BETWEEN 100 AND 200BETWEEN '2018-02-01' AND '2018-02-15'
col BETWEEN 100 AND 200BETWEEN '2018-02-01' AND '2018-02-15'
col BETWEEN 100 AND 200BETWEEN '2018-02-01' AND '2018-02-15'
col BETWEEN 100 AND 200BETWEEN '2018-02-01' AND '2018-02-15'
col BETWEEN 100 AND 200BETWEEN '2018-02-01' AND '2018-02-15'
col BETWEEN 100 AND 200BETWEEN '2018-02-01' AND '2018-02-15'
col BETWEEN 100 AND 200BETWEEN '2018-02-01' AND '2018-02-15'
.find ({$gt : 100,$lt : 200
=AND (B8>100,B8<200)AND (C6>DATE (2021,8,8),C6<DATE (2021,9,10))
Is not between
col NOT BETWEEN 100 AND 200NOT BETWEEN '2018-02-01' AND '2018-02-15'
col NOT BETWEEN 100 AND 200NOT BETWEEN '2018-02-01' AND '2018-02-15'
col NOT BETWEEN 100 AND 200NOT BETWEEN '2018-02-01' AND '2018-02-15'
col NOT BETWEEN 100 AND 200NOT BETWEEN '2018-02-01' AND '2018-02-15'
col NOT BETWEEN 100 AND 200NOT BETWEEN '2018-02-01' AND '2018-02-15'
col NOT BETWEEN 100 AND 200NOT BETWEEN '2018-02-01' AND '2018-02-15'
col NOT BETWEEN 100 AND 200NOT BETWEEN '2018-02-01' AND '2018-02-15'
.find ({$or : [$lt : 100 }},$gt : 200 }}
=NOT (AND (B8>100,B8<200))NOT (AND (C6>DATE (2021,8,8),C6<DATE (2021,9,10)))
Is in list
col IN (a, b, c)IN ((a1, a2), (b1, b2), (c1, c2))
col IN (a, b, c)IN ((a1, a2), (b1, b2), (c1, c2))
col IN (a, b, c)in (col, (a, b, c))IN ((a1, a2), (b1, b2), (c1, c2))
col IN (a, b, c)
col IN (a, b, c)
col IN (a, b, c)
col IN (a, b, c)IN ((a1, a2), (b1, b2), (c1, c2))
.find ({ "field1": { $in : ["12.34.56.255", "12.34.56.254"] }})
=COUNTIF ({"a","b",4},B8)>0
Is not in list
col NOT IN (a, b, c)
col NOT IN (a, b, c)
col NOT IN (a, b, c)notIn (col, (a, b, c))
col NOT IN (a, b, c)
col NOT IN (a, b, c)
col NOT IN (a, b, c)
col NOT IN (a, b, c)
.find ({ "field1": { $nin : ["12.34.56.255", "12.34.56.254"] }})
=COUNTIF ({"a","b",4},B8)=0
GROUP BY
SELECT COUNT (id) FROM tb1 GROUP BY mcSELECT COUNT (id) FROM tb1 GROUP BY mcSELECT COUNT (id) FROM tb1 GROUP BY mcSELECT COUNT (id) FROM tb1 GROUP BY mcSELECT COUNT (id) FROM tb1 GROUP BY mcSELECT COUNT (id) FROM tb1 GROUP BY mcSELECT COUNT (id) FROM tb1 GROUP BY mc
db.personScore.aggregate ([$group : {统计每同学考试记录数 $sum : 1
-
HAVING COUNT (id) > 100HAVING COUNT (id) > 100HAVING COUNT (id) > 100HAVING COUNT (id) > 100HAVING COUNT (id) > 100HAVING COUNT (id) > 100HAVING COUNT (id) > 100-
.sort ((a, b) => b.col1 > a.col1 ? 1 : -1)
ORDER BY col ASC (默认)/DESC ORDER BY col ASC (默认)/DESC ORDER BY col ASC (默认)/DESC ORDER BY col ASC (默认)/DESC ORDER BY col ASC (默认)/DESC ORDER BY col ASC (默认)/DESC ORDER BY col ASC (默认)/DESC
普通查询升序 find ().sort ("score", 1)普通查询降序 find ().sort ("score", -1)聚合查询升序 aggregate ([$sort : { "score", 1 } },
选择1个或多个column排序, 并选择升序还是降序
.slice (offset, offset + limitLen) LIMIT 10LIMIT 0, 10LIMIT 10 OFFSET 0LIMIT 10LIMIT 10 OFFSET 0LIMIT 10LIMIT 0, 10LIMIT 10 OFFSET 0LIMIT 10LIMIT 10 OFFSET 0LIMIT 10LIMIT 0, 10LIMIT 10 OFFSET 0没有LIMIT SELECT TOP 10 col FROM tb1SELECT TOP @pageSize col FROM tb1 WHERE id (NOT IN SELECT top @offset id FROM tb1)FETCH FIRST 10 PERCENT ROWS ONLY OFFSET 0 ROWS FETCH NEXT 10 ROWS ONLY
普通查询 find ().skip (40).limit (10)聚合查询 aggregate ([$skip : 40 },$limit : 10 }
-
Aggregate functions: 聚合函数的操作面向一系列的值,并返回一个单一的值
♥ ♠♣♠♣♥ ♣♣♥♦ --> Group --> ♥ x3 ♠x2 ♣x4 ♦ x1
SUM
tb1.reduce (res, item) => item.colO + res, 0)
SUM (col)SUM (col)SUM (col)SUM (col)SUM (col)SUM (col)SUM (col)
db.personScore.aggregate ([$group : {$max : "$score" $max $min $avg $sum
=SUM (C1:C18)
COUNT 字段条目数tb1.length
COUNT (col)COUNT (col)COUNT (col)COUNT (col)COUNT (col)COUNT (col)COUNT (col)=COUNT (A1:C9)统计A1,C9非空单元格数 COUNTIF (A1:C9, ">2")
COUNT DISTINCT字段条目数
COUNT (DISTINCT col)COUNT (DISTINCT col)COUNT (DISTINCT col)COUNT (DISTINCT col)COUNT (DISTINCT col)COUNT (DISTINCT col)COUNT (DISTINCT col)-
AVG/MAX/MINtb1.reduce (res, item) => Math.max (res, item.colO), tb1[0].col)
AVG (col) MAX (col) MIN (col)AVG (col) MAX (col) MIN (col)AVG (col) MAX (col) MIN (col)AVG (col) MAX (col) MIN (col)AVG (col) MAX (col) MIN (col)AVG (col) MAX (col) MIN (col)AVG (col) MAX (col) MIN (col)=AVERAGE (C1:C18) MAX (C1:C18) MIN (C1:C18)
Scalar functions: Scalar 函数的操作面向某个单一的值,并返回基于输入值的一个单一的值 Date and Time Functions(Scalar functions)
DATEDIFF
DATEDIFF (date1, date2)-
DATEDIFF ('day', startdate, toDate ('2021-09-08'))DATEDIFF (date1, date2)-
DATEDIFF -
db.db1.aggregate ([$project : {DATEDIFF $divide : [$substract : ["$endDate", "$startDate"]加一天 $add : ["$startDate", 24 * 3600000]减一天 $substract : ["$startDate", 24 * 3600000]NOW new Date ()年 $year : "$startDate"季度 $concat : [$toString : {$ceil : {$divide : {$month : "$startDate"年月 $dateToString : {format : "%Y-%m"date : "$startDate"年周 $dateToString : {format : "%Y年第%U周"date : "$startDate"星期 $dayOfWeek : "$startDate"
=DATEDIF (J15,H15,"D")
DATE_ADD(date, INTERVAL expr type)
DATE_ADD (date, INTERVAL 2 DAY)DATE_SUB (date, INTERVAL 2 DAY)-
addDays (col, 20)addMonths (col, 18)DATE_ADD (date, INTERVAL 2 DAY)DATE_SUB (date, INTERVAL 2 DAY)CURRENT_DATE + 2 DAY DATEADD SYSDATE + 1to_date ('2021-09-06', 'yyyy-mm-dd')+1=H15+20
NOW
NOW ()NOW ()NOW ()NOW ()CURRENT_DATE SYSDATETIME ()SYSDATE =NOW () 日期时分 TODAY() 日期
年
date_format (col, '%Y')to_char (col, 'yyyy')formatDateTime (col, '%Y')YEAR (col)TO_CHAR (col, 'YYYY')DATEPART (yyyy, col)TO_CHAR (col, 'yyyy')=YEAR (C1)
季度
CONCAT (YEAR (col), '年第',CEIL (MONTH (col)/3), '季度')to_char (col, 'yyyy年第q季度')CONCAT (toString (toYear (col)), '年第',toString (CEIL (toMonth (col)/3)), '季度')CONCAT (CAST (YEAR (col) AS STRING ), '年第',CAST (CEIL (MONTH (col)/3) AS STRING ) ,'季度')CONCAT (CONCAT (TO_CHAR (col, 'YYYY'), '年第'), CONCAT (TO_CHAR (col, 'Q'), '季度'))CONCAT (DATEPART (yyyy,col), '年第', DATEPART (q,col), '季度')CONCAT (TO_CHAR (col,'yyyy'), '年第', TO_CHAR (col, 'Q'), '季度')=IF (MONTH (H15)<4,"第一季度",IF (MONTH (H15)<7,"第二季度",IF (MONTH (H15)<10,"第三季度","第四季度")))
月
date_format (col, '%Y-%m')to_char (col, 'yyyy-mm')formatDateTime (col, '%Y-%m')FROM_TIMESTAMP (col, 'yyyy-mm')TO_CHAR (col, 'YYYY-MM')CONCAT (DATEPART (yyyy,col),'-',DATEPART (mm,col))TO_CHAR (col, 'yyyy-mm')=CONCATENATE (YEAR (C1),"-",MONTH (C1))
周
date_format (col, '%Y年第%v周')to_char (col, 'yyyy年第ww周')formatDateTime (col, '%Y年第%V周')CONCAT (CAST (YEAR (col) AS STRING ), '年第', CAST (WEEKOFYEAR (col) AS STRING ), '周')CONCAT (CONCAT (TO_CHAR (col, 'YYYY'), '年第'), CONCAT (TO_CHAR (col, 'WW'), '周'))CONCAT (DATEPART (yyyy,col), '年第', DATEPART (ww,col), '周')CONCAT (TO_CHAR (col,'yyyy'), '年第', TO_CHAR (col, 'WW'), '周')=CONCATENATE (YEAR (C1),"年第",WEEKNUM (C1,2),"周")
星期
case when date_format (col, '%w') = '0' then '星期日'when date_format (col, '%w') = '1' then '星期一' when date_format (col, '%w') = '2' then '星期二' when date_format (col, '%w') = '3' then '星期三' when date_format (col, '%w') = '4' then '星期四' when date_format (col, '%w') = '5' then '星期五' else '星期六' end case when to_char (col, 'ID') = '7' then '星期日'when to_char (col, 'ID') = '1' then '星期一' when to_char (col, 'ID') = '2' then '星期二' when to_char (col, 'ID') = '3' then '星期三' when to_char (col, 'ID') = '4' then '星期四' when to_char (col, 'ID') = '5' then '星期五' else '星期六' end case when formatDateTime (col, '%u') = '0' then '星期日'when formatDateTime (col, '%u') = '1' then '星期一' when formatDateTime (col, '%u') = '2' then '星期二' when formatDateTime (col, '%u') = '3' then '星期三' when formatDateTime (col, '%u') = '4' then '星期四' when formatDateTime (col, '%u') = '5' then '星期五' else '星期六' end case when DAYOFWEEK (col) = 7 then '星期日'when DAYOFWEEK (col) = 1 then '星期一' when DAYOFWEEK (col) = 2 then '星期二' when DAYOFWEEK (col) = 3 then '星期三' when DAYOFWEEK (col) = 4 then '星期四' when DAYOFWEEK (col) = 5 then '星期五' else '星期六' end case when DAYOFWEEK (col) = 1 then '星期日'when DAYOFWEEK (col) = 2 then '星期一' when DAYOFWEEK (col) = 3 then '星期二' when DAYOFWEEK (col) = 4 then '星期三' when DAYOFWEEK (col) = 5 then '星期四' when DAYOFWEEK (col) = 6 then '星期五' else '星期六' end case when DATEPART (w,col) = 1 then '星期日'when DATEPART (w,col) = 2 then '星期一' when DATEPART (w,col) = 3 then '星期二' when DATEPART (w,col) = 4 then '星期三' when DATEPART (w,col) = 5 then '星期四' when DATEPART (w,col) = 6 then '星期五' else '星期六' end case when TO_CHAR (col, 'D') = 1 then '星期日'when TO_CHAR (col, 'D') = 2 then '星期一' when TO_CHAR (col, 'D') = 3 then '星期二' when TO_CHAR (col, 'D') = 4 then '星期三' when TO_CHAR (col, 'D') = 5 then '星期四' when TO_CHAR (col, 'D') = 6 then '星期五' else '星期六' end =IF (WEEKDAY (H15,2)=1,"星期一",IF (WEEKDAY (H15,2)=2,"星期二",IF (WEEKDAY (H15,2)=3,"星期三",IF (WEEKDAY (H15,2)=4,"星期四",IF (WEEKDAY (H15,2)=5,"星期五",IF (WEEKDAY (H15,2)=6,"星期六","星期天")))
获得当前日期上周的最后一秒
?
?
addSeconds (toMonday (col), -1))?
?
?
?
?
?
获得当前日期上月的最后一秒
?
?
addSeconds (toStartOfMonth (col), -1))?
?
?
?
?
?
获得当前日期上一季度的最后一秒
?
?
addSeconds (toStartOfQuarter (col), -1))?
?
?
?
?
?
获得当前日期去年的最后一秒
?
?
addSeconds (toStartOfYear (col), -1))?
?
?
?
?
?
String Functions(Scalar functions)
CONCAT
CONCAT (col, col2, ..coln))CONCAT (col, col2, ..coln))CONCAT (col, col2, ..coln))CONCAT (col, col2, ..coln))CONCAT (col, col2, ..coln))CONCAT (col, col2, ..coln))CONCAT (col, col2, ..coln))db.db1.aggregate ([$project : {$concat : [
=CONCATENATE (C1,"-",D1)
INSTR
INSTR (str, substr)INSTR (str, substr)POSITION (str, substr)INSTR (str, substr)INSTR (str, substr)INSTR (str, substr)INSTR (str, substr)?
=FIND ("substr", C1)
LOWER 小写
LOWER (col)UPPER (col)LOWER (col)UPPER (col)LOWER (col)UPPER (col)LOWER (col)UPPER (col)LOWER (col)UPPER (col)LOWER (col)UPPER (col)LOWER (col)UPPER (col)db.db1.aggregate ([$project : {$toLower : "$field1"$toUpper : "$field1"
=LOWER (C1)UPPER (C1)
SUBSTRThe MID and SUBSTR functions equals the SUBSTRING function
SUBSTRING (col, offset, length)offset从1开始而非0 SUBSTR (col, offset, length)SUBSTR (col, offset, length)SUBSTR (col, offset, length)SUBSTR (col, offset, length)SUBSTRING (col, offset, length)SUBSTR (col, offset, length)db.db1.aggregate ([$project : {$substr : ["$field1", 1, -1]
=MID (C1, offset, length)
REPLACE
REPLACE (col, target, replacement)REPLACE (col, target, replacement)replaceAll (col, target, replacement)replaceOne (col, target, replacement)REPLACE (col, target, replacement)REPLACE (col, target, replacement)REPLACE (col, target, replacement)REPLACE (col, target, replacement)db.db1.aggregate ([$project : {$replaceOne : {input : "$field1",find : "co",replacement : "ka"
=REPLACE (C1,2,3,"replacement")从第2个字符开始的3个字符替换成replacement
TRIM 去两边空格
TRIM (col)TRIM (col)TRIM (col)TRIM (col)TRIM (col)TRIM (col)TRIM (col)db.db1.aggregate ([$project : {$trim : {input : " s text "
=TRIM (C1)
LENGTH
LENGTH (col)LENGTH (col)LENGTH (col)LENGTH (col)LENGTH (col)LEN (col)LENGTH (col)db.db1.aggregate ([$project : {$strLenCP : "$field1"
=LEN (C1)
Mathematical Functions(Scalar functions)
ABS绝对值
ABS (col)ABS (col)ABS (col)ABS (col)ABS (col)ABS (col)ABS (col)
db.personScore.aggregate ([$project : {$round : "$field1" } // $round $ceil $floor $abs
=ABS (C1)
CEIL 天花板
CEIL (col)ROUND (col)FLOOR (col)CEIL (col)ROUND (col)FLOOR (col)CEIL (col)ROUND (col)FLOOR (col)CEIL (col)ROUND (col)FLOOR (col)CEIL (col)ROUND (col)FLOOR (col)CEIL (col)ROUND (col)FLOOR (col)CEIL (col)ROUND (col)FLOOR (col)=CEILING (C1, 1)ROUND (C1, 0)FLOOR (C1, 1)
Conditional Functions(Scalar functions)
CASE
tb1.map (item => {let quarter = '第四季度'if (item.col0 < 4) {else if (item.col0 < 7) {else if (item.col0 < 10) {return {
CASE WHEN a THEN b [WHEN c THEN d]... [ELSE e] END CASE WHEN a THEN b [WHEN c THEN d]... [ELSE e] END CASE WHEN a THEN b [WHEN c THEN d]... [ELSE e] END CASE WHEN a THEN b [WHEN c THEN d]... [ELSE e] END CASE WHEN a THEN b [WHEN c THEN d]... [ELSE e] END CASE WHEN a THEN b [WHEN c THEN d]... [ELSE e] END CASE WHEN a THEN b [WHEN c THEN d]... c[ELSE e] END db.getCollection ("personScore").aggregate ([$project : {$cond : {if : {$gt : ["$score", 90]then : "优秀",else : {$cond : {if : {$gt : ["$score", 80]then : "合格",else : "不合格"
用IF 实现,查看上面季度和星期的表达式
IF
IF (表达式, ifTrue, ifFalseOrNull)IF (表达式, ifTrue, ifFalseOrNull)IF (表达式, ifTrue, ifFalseOrNull)IF (表达式, ifTrue, ifFalseOrNull)-
IIF (表达式, ifTrue, ifFalseOrNull)-
=IF (C1>37.5, "发热", "NO")
COALESCE
COALESCE (exp1, exp2,..expn)COALESCE (exp1, exp2,..expn)COALESCE (exp1, exp2,..expn)COALESCE (exp1, exp2,..expn)COALESCE (exp1, exp2,..expn)COALESCE (exp1, exp2,..expn)COALESCE (exp1, exp2,..expn)?
不支持IF (ISBLANK (A1),IF (ISBLANK (B1),C1,B1),A1)
SQL Database
DATABASE List
SHOW DATABASES SELECT datname FROM pg_databaseSHOW DATABASES SHOW DATABASES ?
?
?
?
-
Query TABLE List
SHOW TABLES FROM db1SELECT table_name FROM information_schema.tables WHERE table_schema = 'public'SHOW TABLES FROM db1SHOW TABLES FROM db1?
?
?
?
Query Field List
DESCRIBE tb1SELECT column_name FROM information_schema.columns WHERE table_name = 'tb1'DESCRIBE tb1DESCRIBE TABLE tb1DESCRIBE tb1?
?
DESCRIBE tb1?