Regular Expression
regexper
元字符[已省略了部分不常用的]
| 字符 | 说明 |
|---|
\ | 将下一字符标记为特殊字符、文本、反向引用或八进制转义符。例如,“n”匹配字符“n”。“\n”匹配换行符。序列“\\”匹配“\”,“\(”匹配“(”。 |
^ |  匹配输入字符串开始的位置,在 匹配输入字符串开始的位置,在 中表示排除。如果设置了 RegExp 对象的 Multiline(多行) 属性,^ 还会与“\n”或“\r”之后的位置匹配。 中表示排除。如果设置了 RegExp 对象的 Multiline(多行) 属性,^ 还会与“\n”或“\r”之后的位置匹配。
|
$ | 匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline(多行)属性,$ 还会与“\n”或“\r”之前的位置匹配。 |
+ |  量词[1~n次]一次或多次匹配前面的字符或子表达式。 量词[1~n次]一次或多次匹配前面的字符或子表达式。
|
* | 量词[0~n次]零次或多次匹配前面的字符或子表达式。 |
? | 量词[0/1次]零次或一次匹配前面的字符或子表达式。例如,“do(es)?”匹配“do”或“does”中。 等效于 {0,1}。 |
{n} | 量词匹配正好 n 次。 |
{n,} | 量词匹配至少 n 次。 |
{n,m} | 量词匹配至少 n 次,至多 m 次。例如,“o{1,3}”匹配“fooooood”中的头三个 o。注意:您不能将空格插入逗号和数字之间(如o{1 , 3})。 |
(pattern) |  (Capturing group) 匹配 pattern 并捕获该匹配 (Capturing group) 匹配 pattern 并捕获该匹配
|
(?:pattern) | (Non-capturing group) 匹配 pattern 但不捕获该匹配 |
xxx(?=pattern) |  (Lookaround)执行正向预测先行搜索的子表达式,它是一个非捕获匹配,零宽度匹配。例如,'Windows (?=95|98|NT|2000)' 匹配“Windows 2000”中的“Windows”,但不匹配“Windows 3.1”中的“Windows”。 (Lookaround)执行正向预测先行搜索的子表达式,它是一个非捕获匹配,零宽度匹配。例如,'Windows (?=95|98|NT|2000)' 匹配“Windows 2000”中的“Windows”,但不匹配“Windows 3.1”中的“Windows”。
^(?=[a-z])[a-z0-9]+$能匹配a12,而^(?=[a-z])[0-9]+$不能匹配a12, 因为“(?=[a-z])”只匹配,并不将匹配到的内容保存到最后结果,“(?=[a-z])”匹配成功的位置是位置0,所以“[a-z0-9]+”也是从位置0开始尝试匹配,“[a-z0-9]+”首先尝试匹配“a”
|
(?<=pattern)xxx | (Lookaround)前置 |
xxx(?!pattern) | (Lookaround)执行反向预测先行搜索的子表达式,它是一个非捕获匹配,零宽度匹配。例如,'Windows (?!95|98|NT|2000)' 匹配“Windows 3.1”中的 “Windows”,但不匹配“Windows 2000”中的“Windows”。 |
(?<!pattern)xxx | (Lookaround)前置 |
net|com |  [或] 例如^markli\.(com|net)$ 匹配“markli.com”或“markli.net”。要匹配 |,请使用 \| [或] 例如^markli\.(com|net)$ 匹配“markli.com”或“markli.net”。要匹配 |,请使用 \|
|
[xyz] | [字符集]匹配包含的任一字符。 |
[^xyz] | 反向字符集。匹配未包含的任何字符。 |
[a-z] | [字符范围]匹配指定范围内的任何字符。(-字符如果在字符范围前,则表示 他本身,无需转义,如果在两个字符中间,则表示两个字符的区间)例如,“[a-z]”匹配a到z范围内的任何小写字母。还有[a-zA-Z0-9],⚠️ 注意 [A-z] 不等于[A-Za-z] 而是 [A-Z\[\\\]^_`a-z],charCode 65-122 |
[^a-z] | 反向范围字符。匹配不在指定的范围内的任何字符 |
\b | 匹配一个字边界(border),即字与空格间的位置。例如,“er\b”匹配“never”中的“er”,但不匹配“verb”中的“er”。再如“\byo”匹配“I love you”第三个字you的yo |
\B | 非字边界匹配。“er\B”匹配“verb”中的“er”,但不匹配“never”中的“er”。 |
\d |  [数字]数字字符匹配。等效于 [0-9]。 [数字]数字字符匹配。等效于 [0-9]。
|
\D | [非数字]非数字字符匹配。等效于 [^0-9]。 |
. | 匹配除换行“\n”之外的任何单个字符。 |
\n | 换行符(newline)匹配。 |
\r | 匹配一个回车符(return)。 |
\s | 匹配任何空白字符,包括空格(space)、制表符、换页符等.与[ \f\n\r\t\v]等效。 |
\S | 匹配任何非空白字符。与 [^ \f\n\r\t\v] 等效。 |
\w | [字母数字下划线]匹配any word character,包括下划线。与“[A-Za-z0-9_]”等效。 |
\W | 与任何非word character匹配。与“[^A-Za-z0-9_]”等效 |
\xn | 此处的 n 是一个十六进制转义码。例如,“\x41”匹配“A”。“\x041”与“\x04”&“1”等效。允许在正则表达式中使用 ASCII 代码。 |
正则表达式的引擎
当发现复制来的正则在JavaScript里正常,而在PHP却无法使用的时候,为什么会这样,慢慢的你就知道正则流派与引擎了
| 引擎类型 | 程序 |
|---|
| DFA | Awk(多数版本)、egrep(多数版本)、flex、lex、Mysql |
| POSIX NFA | |
| 传统NFA | GUN Emacs、JAVA、GREP(多数版本)、less、more、PREL、PHP(3套)、Python、ruby、sed(多数版本)、vi |
| DFA/NFA混合 | Gun awk、gun grep/egrep |
♠ DFA引擎不需要回溯(Backtracking),所以匹配快速,也不支持捕获组(所以也就不支持后向引用和$number这种引用方式)
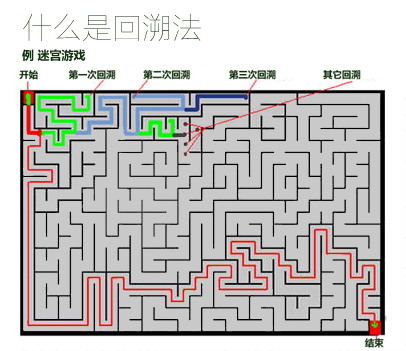
♣ POSIX NFA主要指符合POSIX标准的NFA引擎,它的特点主要是提供longest-leftmost匹配,也就是在找到最左侧最长匹配之前,它将继续回溯。
非贪婪模式(或者说忽略优先量词,匹配优先量词和忽略优先量词实际上也就是我们说的正则表达式中的贪婪模式和非贪婪模式)对于POSIX NFA同DFA一样,是没有意义的。
♦ 传统NFA引擎 - 大多数语言和工具使用的,它有一些DFA不支持的特性:
1.捕获组、后向引用和$number引用方式
2.Lookaround: (?=…)、(?!…)、(?<=…)、(?<!…)
3.忽略优先量词: ??、*?、+?、{m,n}?、{m,}? 默认的是匹配优先量词,与匹配优先量词相反,忽略优先量词的意思是尽可能少的匹配
4.占有优先量词: ?+、*+、++、{m,n}+、{m,}+,匹配优先最终不成功还可回溯为忽略,但占有优先一旦匹配就封住退路,不准回溯,目前仅Java和PCRE支持(php有pcre)
5.固化分组 Atomic Grouping(?>…)
NFA引擎是“猴急”的,它会很急切的进行表功,报告它找到的第一个匹配
你可以作如下测试:将正则表达式"(regex|regex not)"应用到字符串"regex not"。如果匹配的结果是regex,则引擎是NFA。如果结果是regex not,则是DFA。NFA找到后锁定,返回。DFA继续下一个,找最长结果
preg_match('/date:(\d{4}|\d{4}-\d{2}-\d{2})/','date:2016-05-19',$match);
echo $match[1];
preg_match('/(<div>.+</div>)/','<div>testtest</div> <div>test</div>',$match);
echo htmlspecialchars($match[1]);
preg_match('/(<div>.+?</div>)/','<div>testtest</div> <div>test</div>',$match);
echo htmlspecialchars($match[1]);
preg_match('/(ab??)/','ab',$match);
echo $match[1];
preg_match('/(ab??c)/','abc',$match);
echo $match[1];
固化分组和占有量词
假设我们有这样的需要,把类似 3.690000023 的小数保留两位小数,类似 2.3563895 的小数保留三位小数,也就是说如果小数的第三位是 0, 则保留两位小数,如果是非 0, 就保留三位小数
echo preg_replace('/(\.\d\d[1-9]?)\d*/','$1',$number)
echo preg_replace('/(\.\d\d[1-9]?)\d+/','$1',$number)
echo preg_replace('/(\.\d\d(?>[1-9]?))\d+/','$1',$number);
echo preg_replace('/(\.\d\d[1-9]?+)\d+/','$1',$number);
太多的回溯会使得你的程序阻塞
字符串:<div>xxxxx…xxxx</div><div>test</div>(...处是10W个字符)
表达式:<div>.+?</div>
当遇到忽略优先量词+?,中间每个字符处都记录一个备选状态,对于10W个字符,会占用相当大的内存
回溯次数多,PHP的堆栈溢出,好在有回溯次数限制(pcre.backtrack_limit),不然或许又成为一个溢出漏洞了

ReDoS(正则表达式拒绝服务攻击)
通常是由于正则表达式的回溯机制导致的。
1. 灾难性回溯: 正则表达式在匹配时,会尝试所有可能的匹配路径,导致计算量呈指数级增长。
2. 贪婪匹配: 使用*、+、{n, m}等匹配符号时,可能会导致大量的回溯尝试
3. 嵌套结构: 如(a+)+这样的表达式,会让匹配过程变得复杂,容易触发ReDoS攻击
定义一个与此同时表达式^(a+)+$ 来对字符串aaaaX匹配。使用NFA的正则引擎,必须经历2^4=16次尝试失败后才能否定这个匹配。同理字符串为aaaaaaaaaaX,就要经历2^10=1024次尝试。
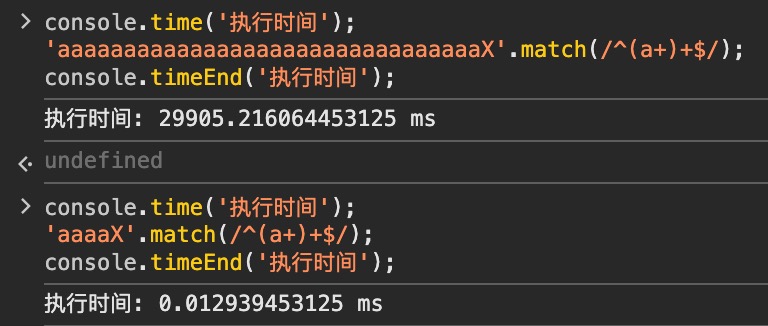
攻击者可以输入特定的长字符串,使得正则匹配过程变得极其缓慢,从而拖垮服务器
正则表达式性能设计
1.先大后细
举手机号的例子,先界定\d{11};再细化为1[358]\d{9},逐步细化,一点一点地消除误匹配(做减法)
2.环保不浪费
只要能确定范围的,例如\w,就不要用点号;只要能够预测重复次数的,就不要用任意量词。
每使用一个普通括号()而不是非捕获型括号(?:…),就会保留一部分内存等着你再次访问。
3.少用多选分支
c[a-f]t 与c(a|b|c|d|e|f)t (有6次回溯)
4.适当使用边界字符
^,$,\b
5.分支顺序
最可能出现的放到分支最前面
常用例子
| 正则表达式 | 匹配内容 | regexper |
|---|
/^(?:25[0-5]|2[0-4]\d|1\d\d|[1-9]\d|\d)(?:\.(?:25[0-5]|2[0-4]\d|1\d\d|[1-9]\d|\d)){3}$/ | Validate IP address | 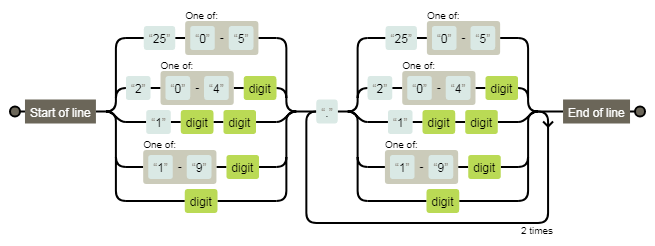 |
/^[a-zA-Z0-9.!#$%&'*+/=?^_`{|}~-]+@[a-zA-Z0-9](?:[a-zA-Z0-9-]{0,61}[a-zA-Z0-9])?(?:\.[a-zA-Z0-9](?:[a-zA-Z0-9-]{0,61}[a-zA-Z0-9])?)*$/ | Validate Email address(W3C HTML5 spec) | Alexa email regex issue |
/(\w+):\/\/([^/:]+)(:\d*)?([^# ]*)/ | Validate URL
反向匹配URL,/(\w+)可匹配HTTP 然后:\/\/匹配:// 然后是[^/:]+,即非/:的字符匹配中间域名然后是(:\d*)?非贪心匹配端口号,然后匹配不包括 # 或空格字符的任何字符序列 | |
/^\d{6,8}$/ | 只能输入6~8位的数字 | |
/^[0-9-]+$/ | 只能输入数字和- | |
vim 替换
vim 的替换需要另外的转义 \+, \{n,m}, \(
:%s/[a-z]\+[^a-z,]{2,}\([a-z]\)/\1/g